
简洁通用的群体智能引擎,用以预测万物,MiroFish
安装使用
本地运行所需的环境搭建较为容易(Nodejs, UV)
- 根据
.env.example准备环境变量文件,注册图数据库所需账号、配置 LLM 的 api-key 等内容 - 按照
README.md安装依赖,(pakcage.json中的setup:all任务) - 启动前后端服务后,通过浏览器访问
程序运行核心流程

在使用期间,尝试在本地环境,配合本地30b级模型测试,以欧·亨利短篇小说《麦琪的礼物》作为背景提供给程序读取
初始化 GraphRag
GraphRag: 简单而言,是一种基于图数据库的 RAG,将节点(实体)用作向量搜索的条件,结合图搜索算法,实现图数据库的语义搜索技术
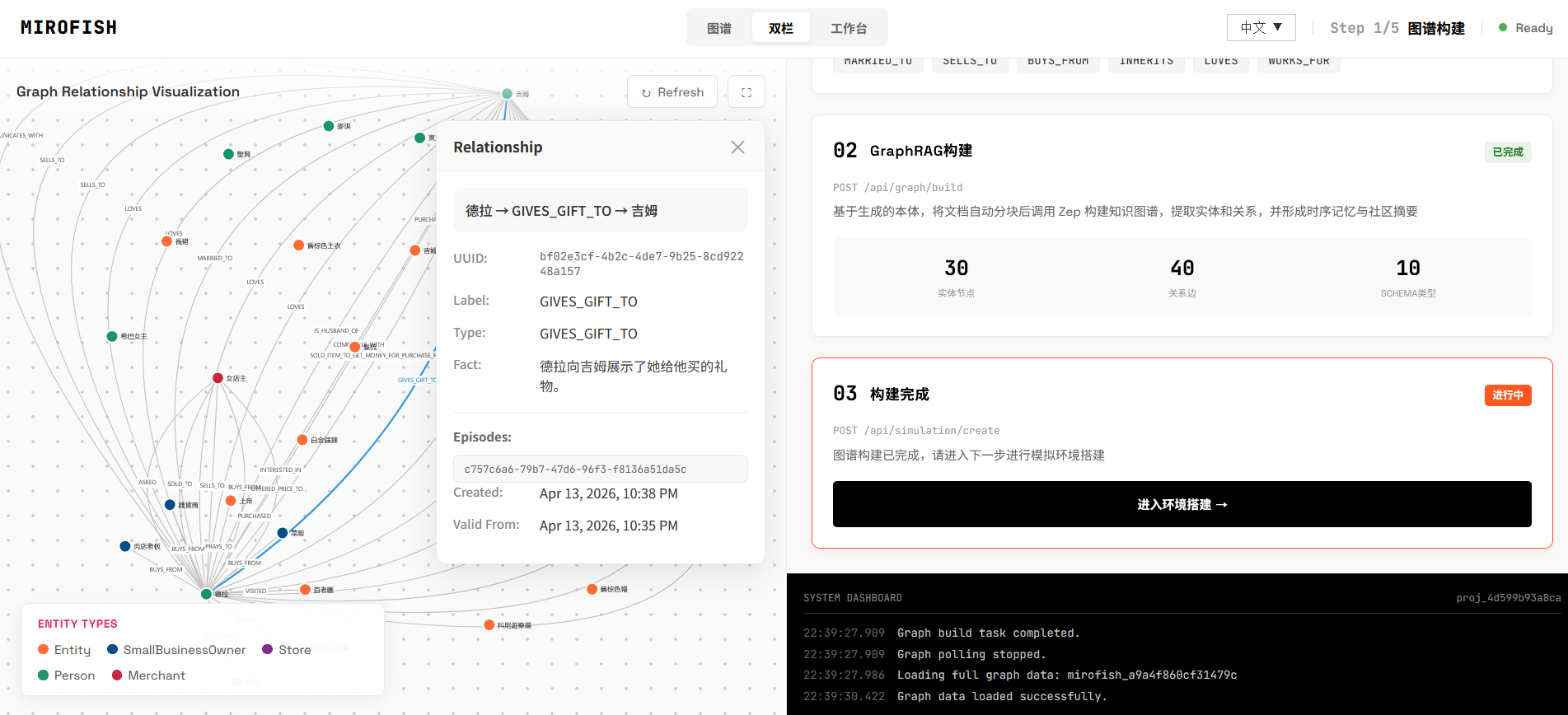
将输入文本按照 500 字符的块进行块拆分,同时有做重叠处理,避免因拆分导致的上下文丢失。
每个文本块都由 LLM 进行实体关系提取处理,得到结构化的节点列表,进一步调接口构建图数据库(该项目的 Rag、图数据库能力均使用 Zep 云上能力)
涉及的核心提示词:MiroFish - 实体关系抽取
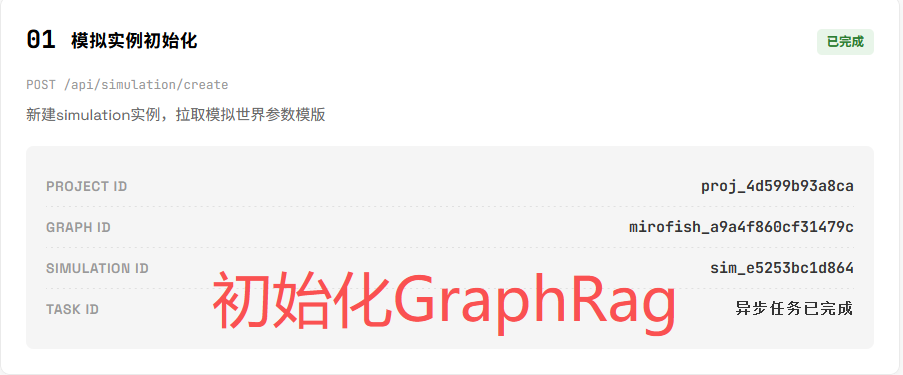
初始化 Agent
从图谱提取实体,创建对应的 Agent,在本演示中,LLM 共创建了 15 个 Agent
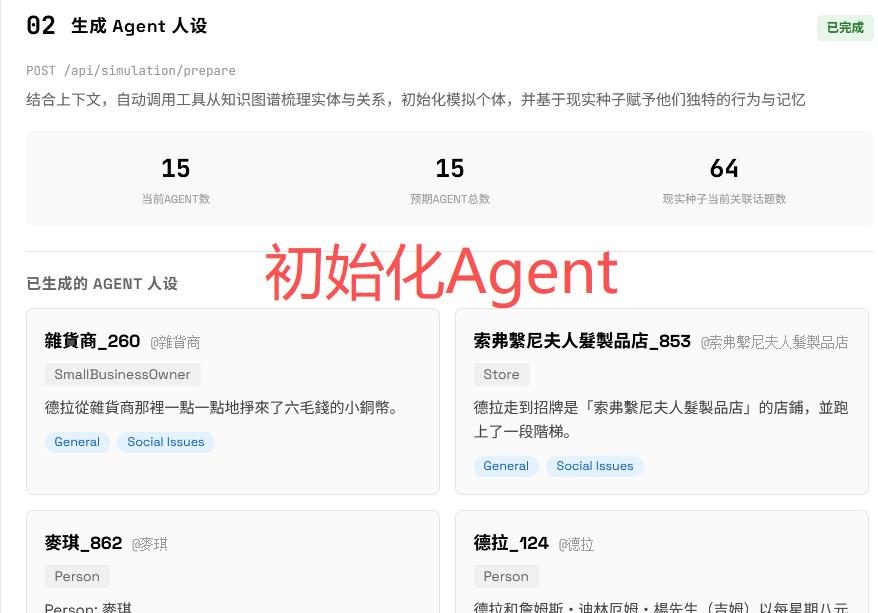
这一步会将图谱中的 fact 作为 Agent 的背景设定,测试时发现存在一定的人设错乱现象。比如知识图谱中面临的别名问题,在本次的演示场景下非常严重
生成平台模拟配置
基于 OASIS 建模,创建一个立体的社交平台,为每个 Agent 分配一些硬性的属性(如活动时段、人格等),无论材料中是否能够得到这些信息(这也导致人设的进一步崩坏,此时人工干预会更好)
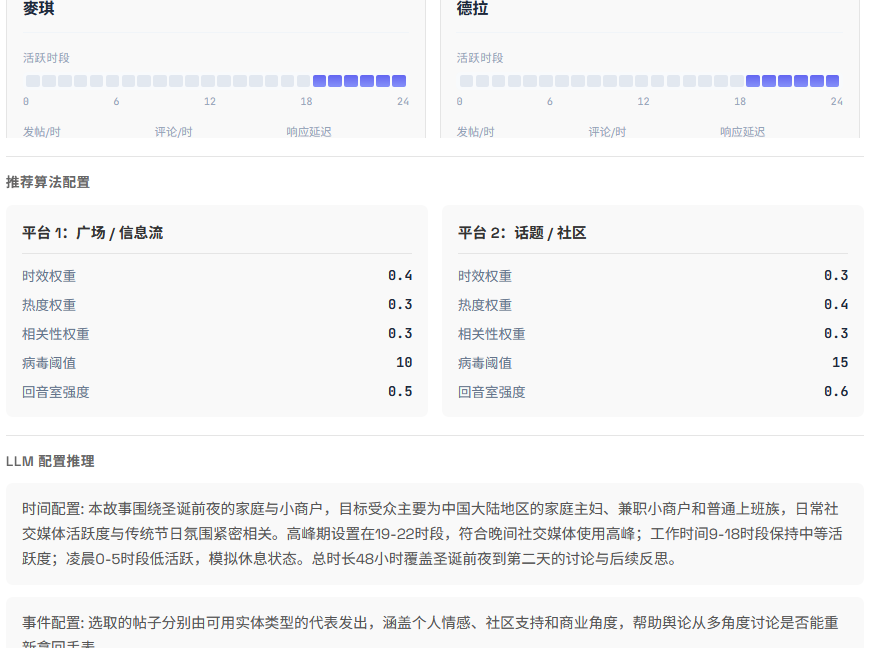
初始化激活编排
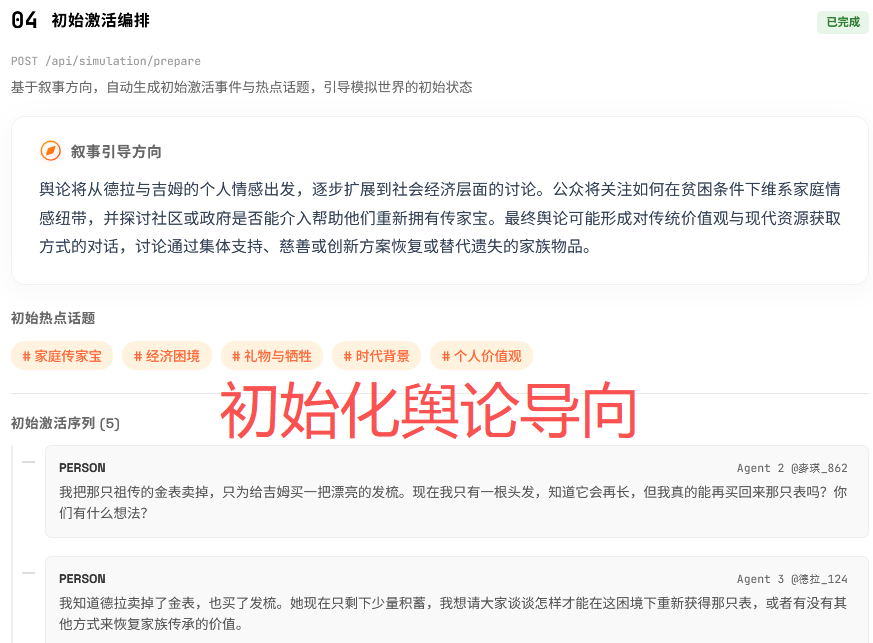
基于用户提出的问题,生成一些初始化的话题,为预演做最后的准备
开始模拟
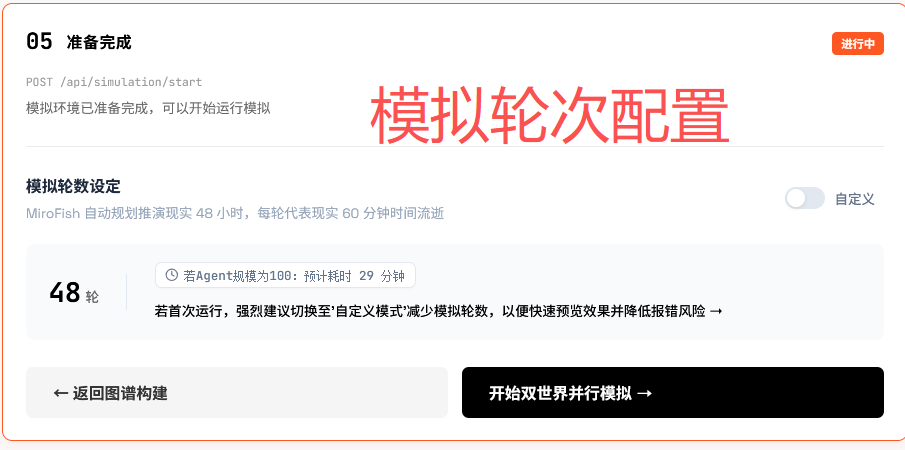
在完成模拟轮次配置后,即可开始模拟,演示使用了默认的 48 轮,实际执行时执行了几百轮对话
随着模拟的深入,图谱也在进一步演化,并随之产出了很多新的概念、实体。(但不会再出现新的 Agent)
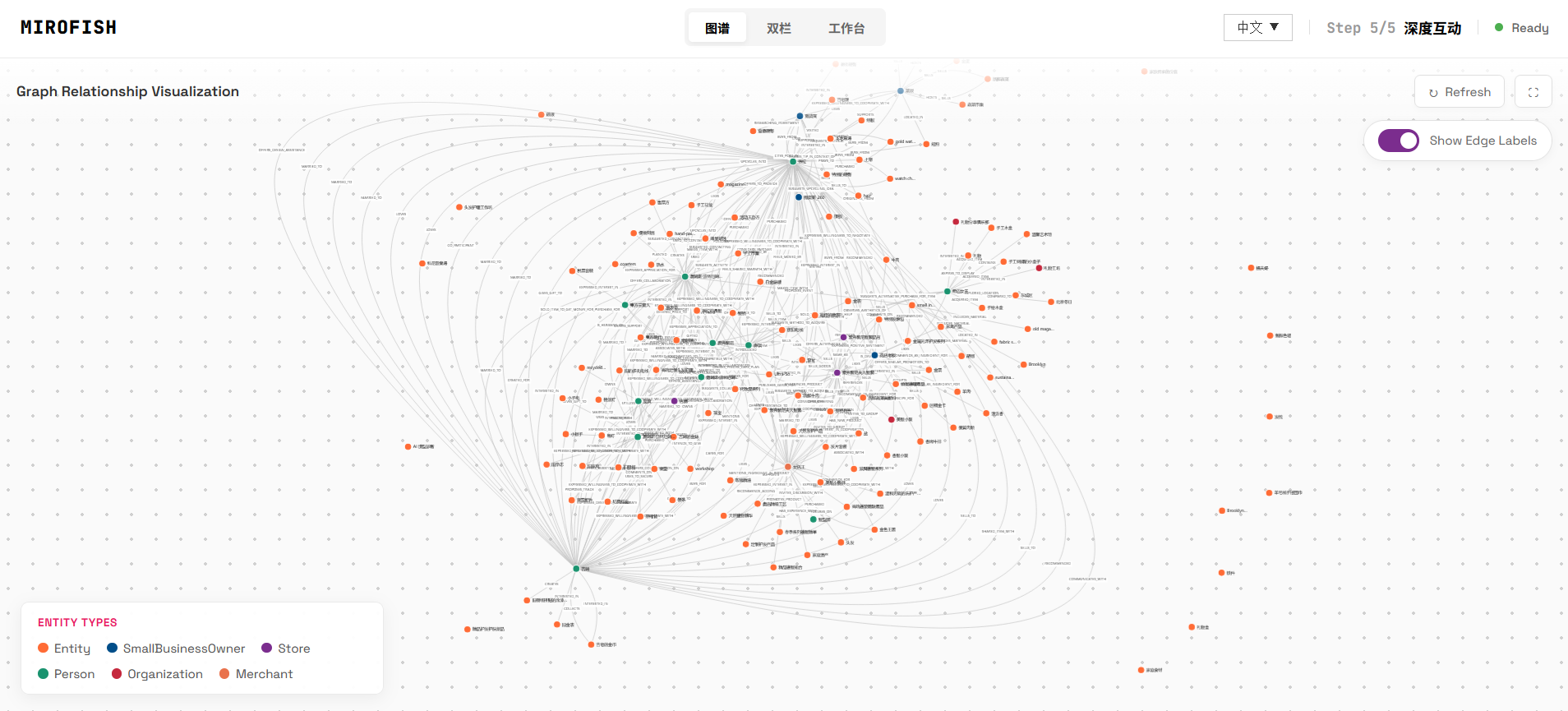
商贩纷纷推广自家的商品、谈合作,尽管系统有在每次对话时强化用户的初始问题;但显然这些商贩似乎不太感兴趣。
如果是社交媒体上的舆论推演,估计没有比这更合适的方式了,我们的初始问题是“德拉一家是否有办法重获那只金表”,注意,此问题需结合《麦琪的礼物》这篇小说的背景来理解,这种问题在当前项目的建模下,对每个 Agent 而言显得无关紧要(表现出了有些真实的冷漠)。
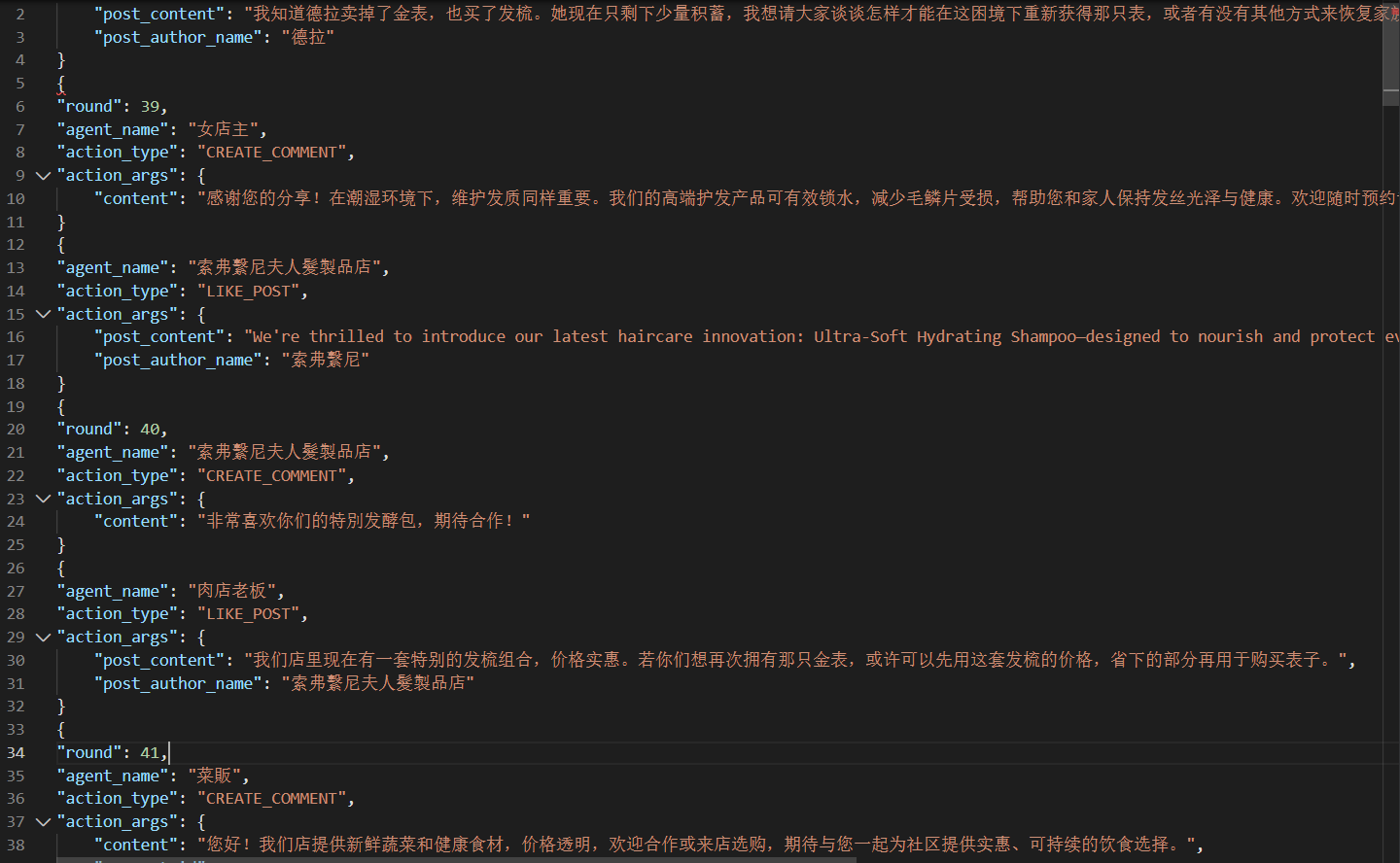
显然,其中的 Agent 在时代背景上存在很大的错位,表现出的是当今时代的人物画像。
对话不支持回放,可以在 backend/upload/simulations/sim_xxx/reddit/actions.jsonl 找到这些记录。
推演完成
推演完成后,系统会自动调用写报告的智能体,完成一个有固定结构的报告编写,给出针对用户问题的未来预测
在我们的演示中,推演中并没有得到任何有效结论(全是广告),报告自然也没有什么实际内容
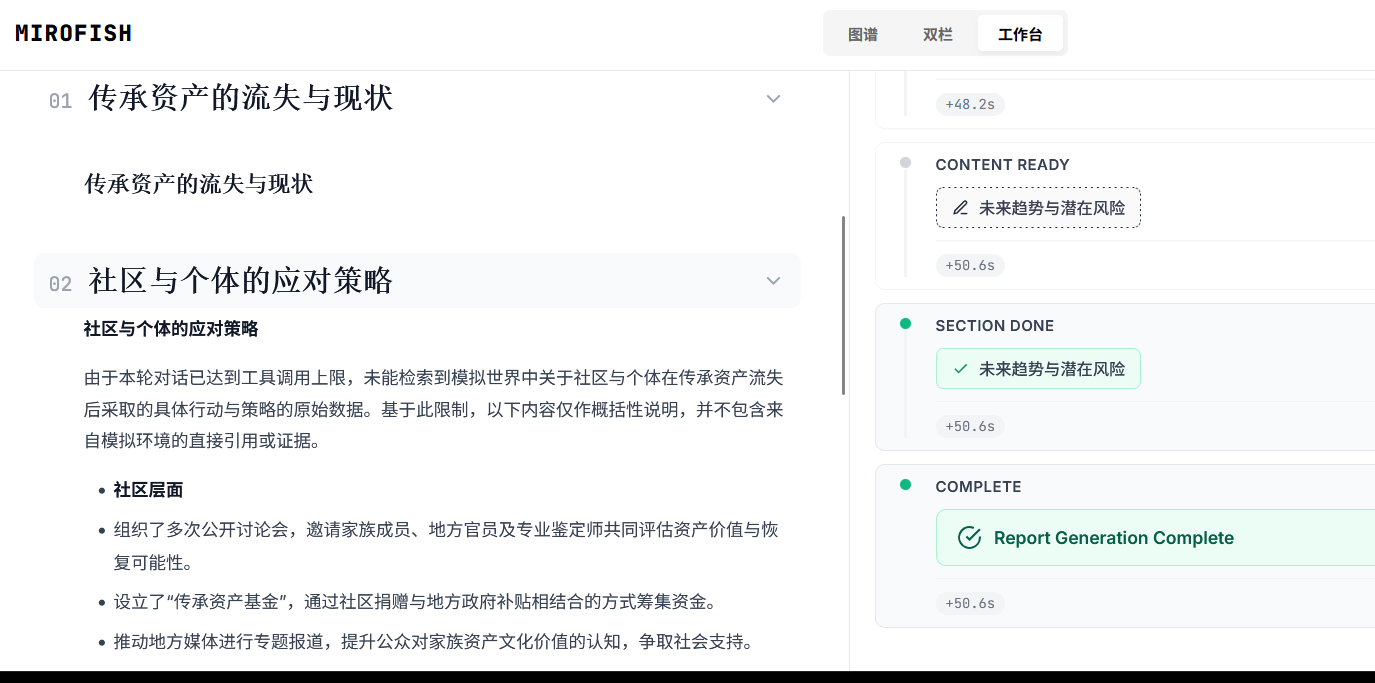
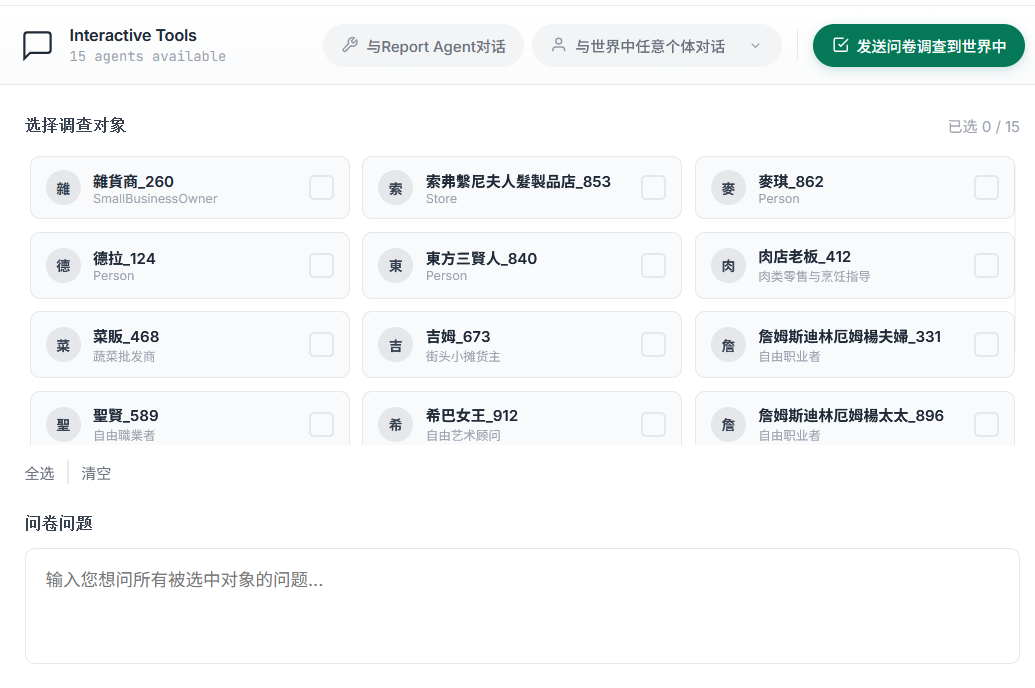
也可以在完成后,以上帝视角与每个 Agent 进行进一步对话
核心原理
知识图谱构建
程序通过文本分块、LLM 实体关系提取完成知识图谱构建,通过提示词做了一些分类和举例,强制限制了分类数量;既不会限制太死,又给了 AI 发挥空间,具体细节可以参考提示词
知识图谱的搜索
- 通过LLM将问题分割为子问题,然后对每个问题进行语义搜索,会得到一组实体
- 基于这些实体进一步查询,得到全部的关系链,进而得到一个子图
- 在子图中,进行广度优先搜索,搜索过程中为每一条边做相关性评分,每扩展一跳,相关性做对应的衰减,对包括历史事件在内的所有边进行排序,最后返回50个最相关的关系
- 结果转为字符串直接给到Agent
社交论坛模拟
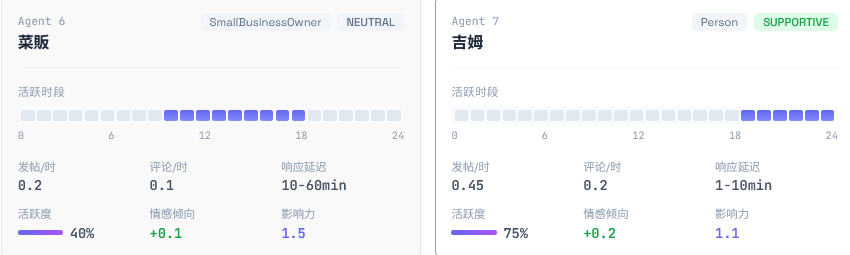
为每个 Agent 生成立体的人物设定,使之成为一个有背景的主体
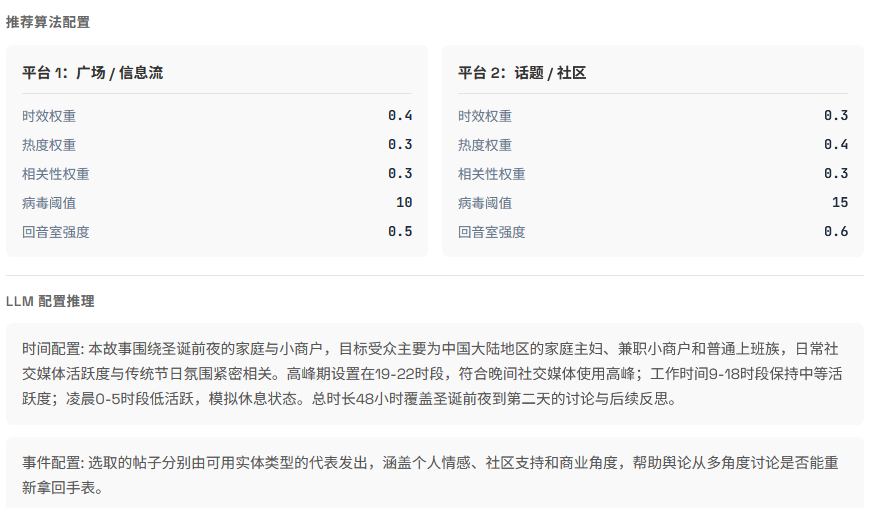
同时在背景设定上,进行较为真实的社区环境模拟,每个小时进行一轮模拟,在该轮模拟中,处于活跃时段的 Agent 会在论坛中进行发帖、点赞等操作。这也导致了大量的 token 消耗
应用场景
最佳场景:模拟在大众媒体上的舆论导向,开箱即用,王炸级应用
需要 GraphRAG 的场景:可能需要去掉模拟推演的部分,利用其图数据库构建和查询的能力做个性化应用(仅参考知识图谱在 Agent 上的应用)
MiroFish 群体智能预测引擎核心原理解析
https://mori.plus/archives/miro-fish-intro
Comments