Guava
可以理解为一个 ConcurrentHashMap 的封装,采用分段锁,实现了缓存回收,并支持 LRU。
缓存失效机制
-
expireAfterWrite/expireAfterAccess (项目中采用)
缓存在一定的时间内没有读写(访问)后会被回收。Guava 严格保证同一时间只有一个线程对缓存进行读写(访问)。
Guava 内部维护写队列和访问队列,大量线程访问一个 key 时,Guava 会将他们拦截放到队列中维护,一时间只有一个线程会进行 load,其他线程被阻塞,直到缓存生成。形成对击穿的保护,
但可能导致大量线程阻塞,性能上有一定损耗。
-
refreshAfterWrite
在写之后刷新,即多个线程访问一个时,读取线程不会等待更新线程将数据更新到缓存,直接使用旧值。对上述情况的优化。
这种异步刷新也可以对大量缓存同时失效的情况加以保护。
但是缓存长时间不刷新后偶尔访问一次可能得到很久之前的值。
分段锁设计
实现与 JDK1.7 及之前的 ConcurrentHashMap 的分段锁类似,一个大的分段 hash 表,同 hash 上用链表存储,有扩容的支持。
分段 hash 锁控制:同一时间只有一个线程对一个段进行写入,读取不受限制,可以降低阻塞、尽量锁太密导致的频繁加解锁。
Caffeine
- 对标 Guava,从 Guava 过渡十分方便(换一下构建器的类名,该怎么用还怎么用)。
// 构建 Guava
Cache<String, Object> GUAVA_CACHE = CacheBuilder.newBuilder()
.xx() // 其他构建参数
.build();
// 构建 Caffeine
Cache<@NonNull String, @NonNull Object> CAFFEINE_CACHE = Caffeine.newBuilder()
.xx() // 其他构建参数
.build();
// 使用方法一致
GUAVA_CACHE.put(key, value);
GUAVA_CACHE.getIfPresent(key)
CAFFEINE_CACHE.put(key, value);
CAFFEINE_CACHE.getIfPresent(key);
-
性能更高,与 Guava 有几倍的性能差。
-
被 Spring5,Springboot 2.x 作为默认缓存采用。
Caffeine 高性能原理
W-TinyLFU 算法
-
LRU 最近最久未使用:无法很好应对遍历的场景
-
LFU 最不经常使用:需要记录频率,比较耗内存,而且对突发的高频访问效果不佳(新的热点数据需要一段时间后频率记录值才会高起来)
布隆过滤器的变种
不需要知道确定的访问频次,大概即可,符合布隆过滤器的特点。
W-TinyLFU 维护一个计数的布隆过滤器(每个槽都计数,而不是布尔值)。
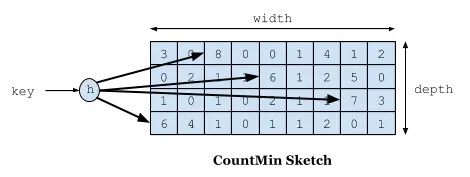
访问 key 时,按照一定的 hash 规则(未对该规则深入探索)进行映射,将映射到的各个槽都加1,获取频率时,取各个槽的最小值。
当总体更新的次数达到阈值后,将所有的计数都除以2,可以保证频率不会被过去的数据占坑,即保证数据的“新鲜度”。
解决了 LRU 遍历造成缓存污染的问题,遍历一遍所有有数据的槽都会增加。
缓解了 LFU 突发高频,因为除以 2(这个 2 是有实验验证的,具体没做深究),历史的频次数据不会一直在这里面碍事。
窗口
为更好解决数据稀疏高频的访问,W-TinyLFU 提出了 Window 的概念(也称 Eden),使用很小一部分内存(默认 1%)作为窗口,在其中使用 LRU 算法。在突发高频的场景,因为 LRU 的特点这种数据会停留在窗口中,不会因为频次没上去被干掉。这些高频数据不再访问后,也会逐渐被淘汰而不是一直占着地方。
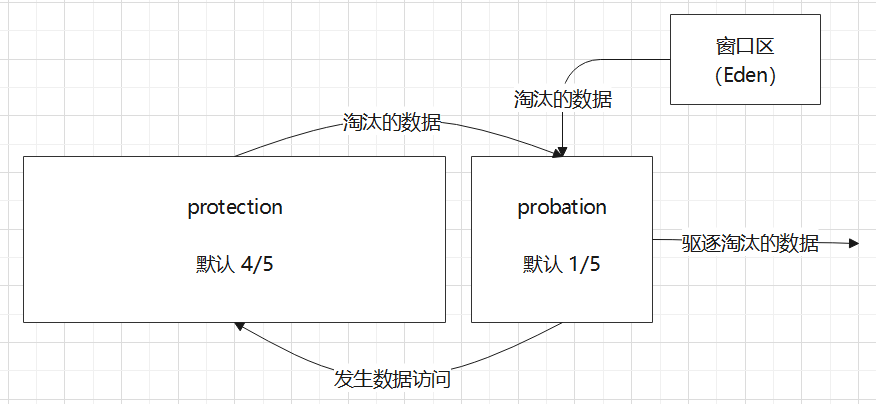
新缓存会首先进入窗口,窗口满了之后,淘汰后与 S-LRU (余下99%,分段 LRU)中项目进行竞争,该区域分为 probation 和 protection 区,淘汰发生在 probation 区。从 protection 中淘汰的数据也会进入 probation 参与竞争
expireAfter 过期策略与时间轮
expireAfter 策略与 expireAfterWrite/expireAfterAccess 互斥。
因为默认实现是固定的过期时间,使用普通的队列即可实现。expireAfter 允许自定义过期时间,普通的队列则需要排序,消耗太大。

Caffeine 采用多层时间轮控制,数据来的时候,将其根据过期时间放到对应的槽内。
一个单位时间内,处理时间轮上一个槽内链表中的所有过期操作。一个轮处理完处理下一轮。
Comments