
使用 Redisson 延迟队列导致内存泄漏
使用 Redisson 延迟队列导致内存泄漏
问题现象
长假期间,服务节点突然开始重启,且没有其他报警,紧接着其他节点也陆续开始重启,全部节点无一幸免,所幸业务上无实际影响,但服务明显出了什么状况。
事后查看节点 JVM 情况,发现节点的内存占用在启动后缓慢上升。接近耗尽后开始频繁 FullGC,尽管 JVM 尽了最大努力仍然没有效果,最终 Pod 重启,服务恢复。至此开始怀疑程序中存在内存泄漏问题,这也能解释为什么平常有迭代的时候没有问题,放个长假就开始搞事情:
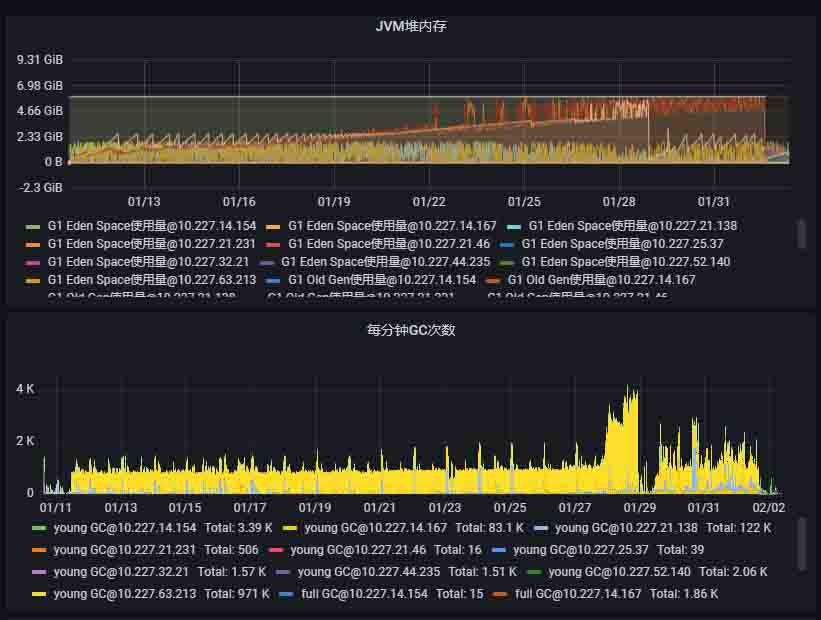
问题定位
Dump 文件获取
节后查看了近期 80 个迭代的代码改动,均未发现疑点。而且因为节点已经重启,没办法获取堆转储文件。只能等下次报警时来想办法进行 dump。
几天后的一个午后,新一轮重启开始了,Exit code 137,说明属于 OOM 退出:
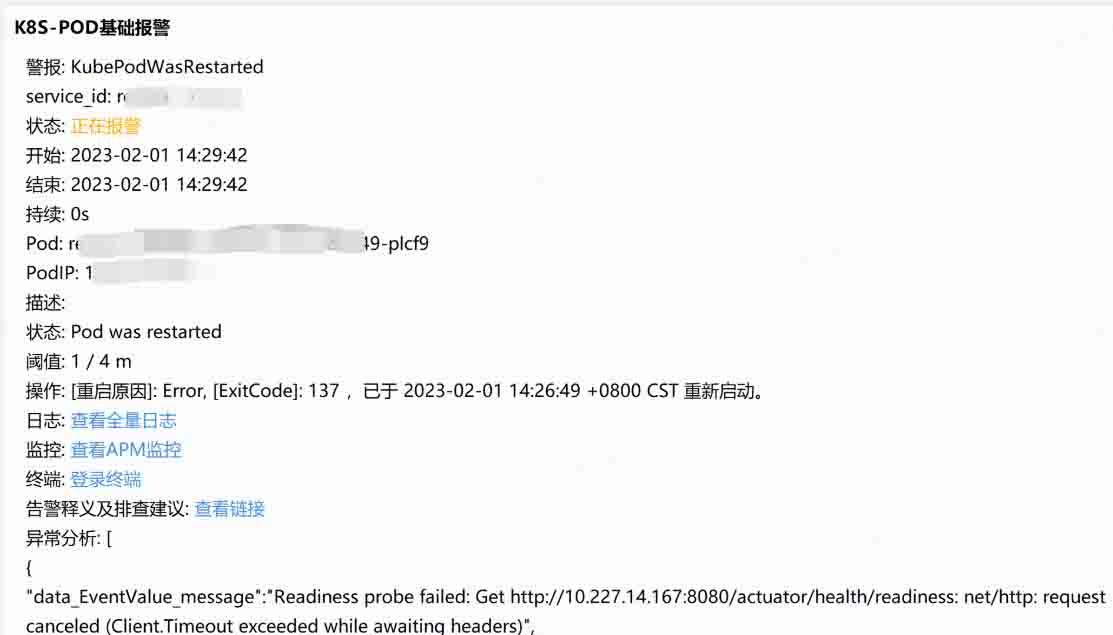
说时迟那时快,报警产生后,登录线上还幸存的节点,使用 jmap 指令对服务进程进行 dump:
- 查询服务的进程 PID:
jps得到服务的 PID 为 1 - 使用 jmap 进行堆转储:
jmap -dump:format=b,file=/服务日志路径/xxx.dump 1 - 执行此步骤期间会 STW,且因为时间较长,容器会自动重启。
- 重新登录重启后的 pod,把 dump 文件搞下来,这里使用开发机做中转:
- 使用 scp 传递文件(或 rsync):
scp /服务日志路径/xxx.dump user@开发机IP:/xxx/ - 删掉线上机器的 dump 文件
- 登录开发机,下载转储文件到本地
- 使用 scp 传递文件(或 rsync):
这里需要注意的是:
- dump 不能放置于 /tmp 目录下,否则重启会被清除,这里使用服务日志路径,确保不会因为重启被干掉
- 如果为重要线上服务不能直接转储,而是需要设定 jvm 启动参数,异常时自动转储。
问题分析
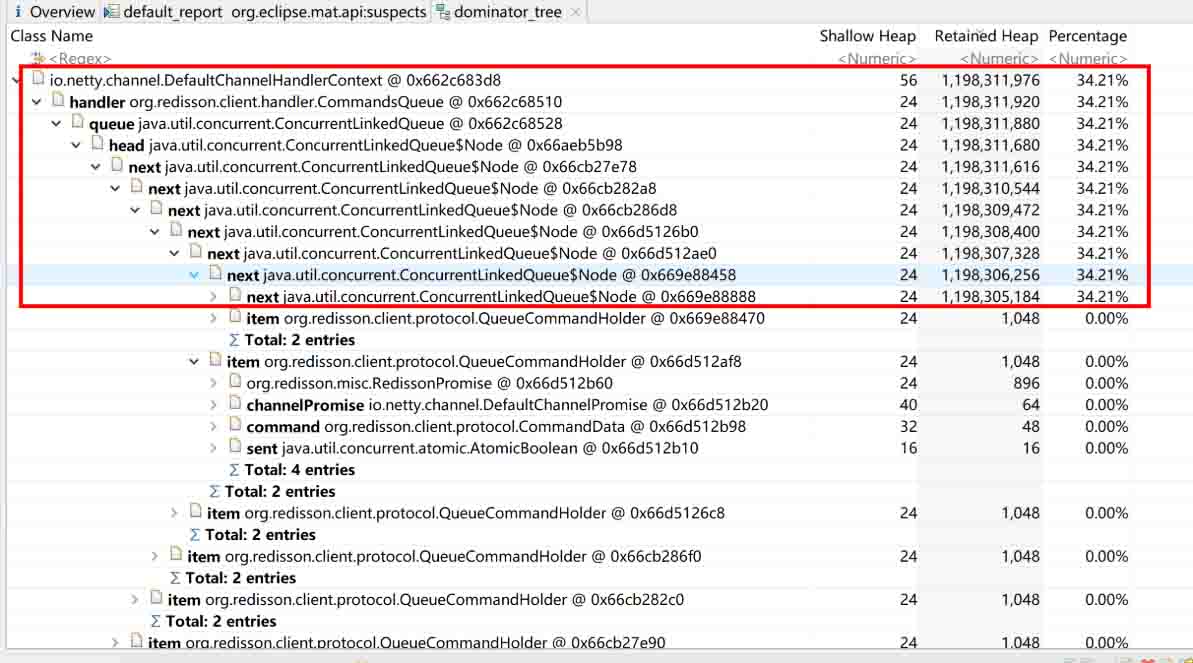
使用 MAT 工具(或其他分析工具)分析 dump 文件发现,有三个大对象耗尽了堆空间
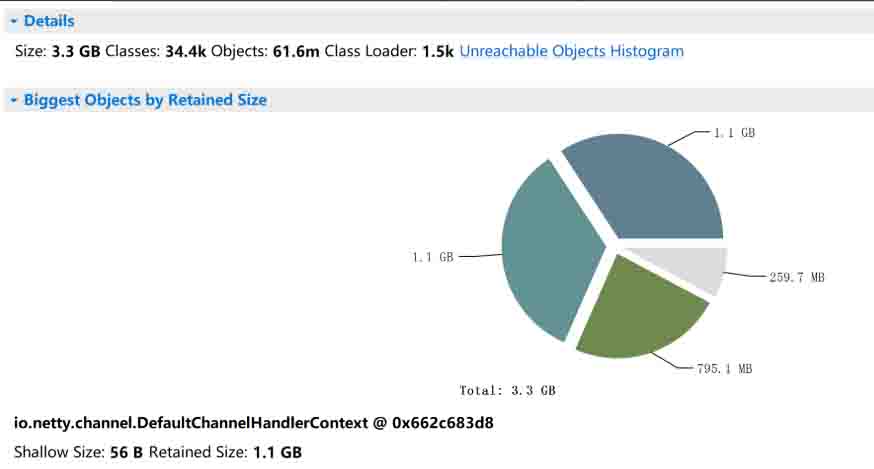
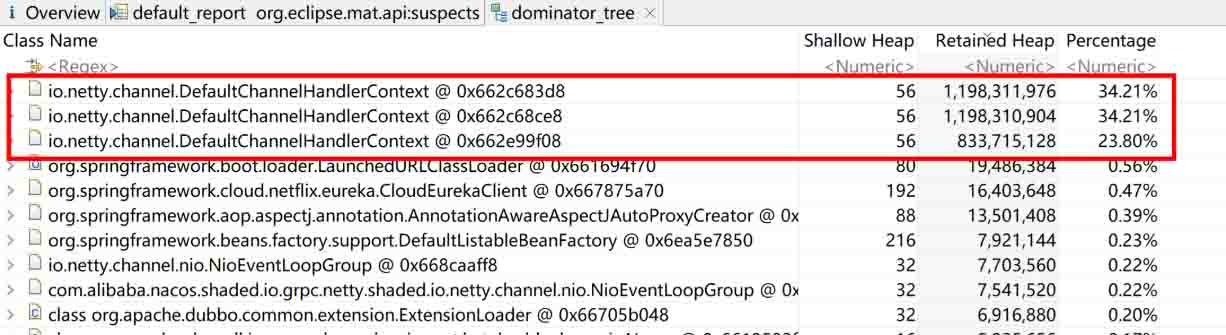
初步定位发现为 Redisson 的相关操作导致,在内存中生成了巨大的类似链表的结构。进一步分析链表的节点数据,发现每个节点均为一个 redisson 的 PING 指令对象,至此可基本定位到问题出在 redisson 中。
代码追踪
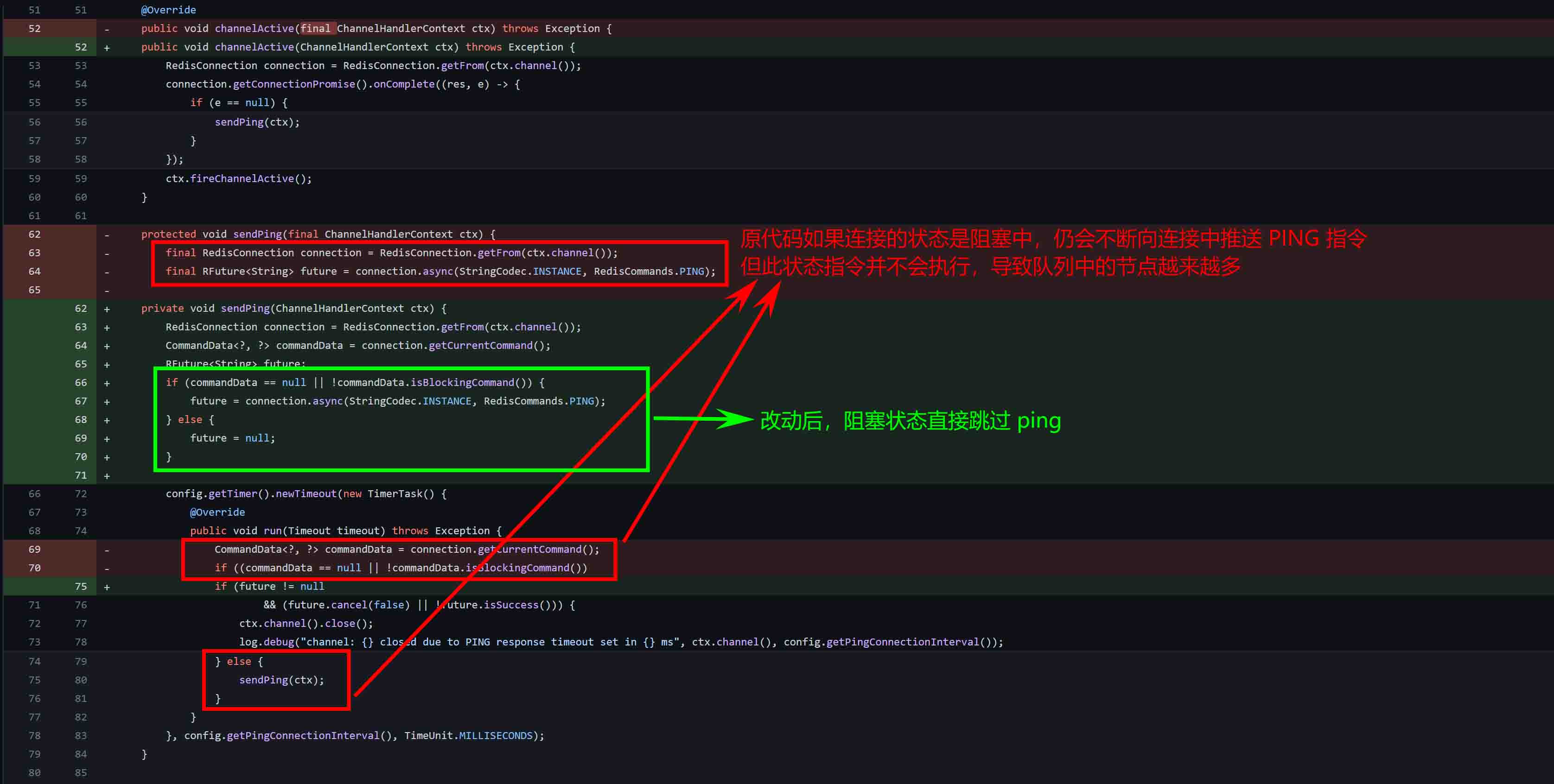
通过分析发现,在 3.12.5 以下版本,使用 Redisson 的阻塞队列(延迟队列)时,会遇到这个问题。除非阻塞状态解除,阻塞的 Ping 指令才能有机会释放。
问题解决
至此,问题的解决办法已显而易见,更新 Redisson 到 3.12.5 以上版本问题可以解决,可以参考:关于该问题修复的 Commit。
修改后,观测服务节点即使长时间运行也不会 OOM 重启。
附录:Redisson 使用延时队列
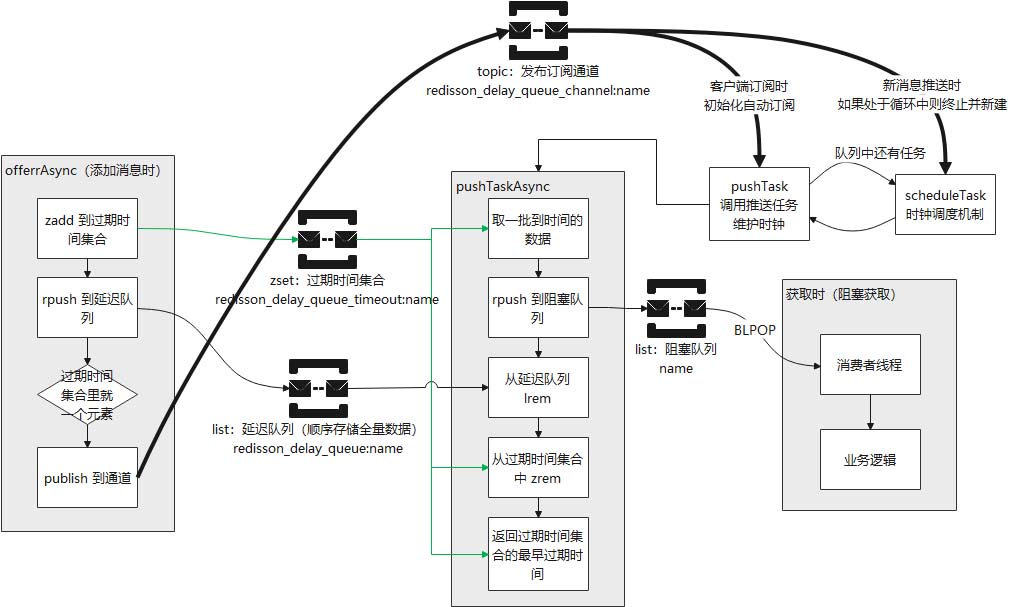
使用 Redisson 的延时队列、阻塞队列会触发以上问题,这里延时队列使用触发阻塞的原因:
使用示例
通过下面的办法来初始化:
// ...
@Resource
private RedissonClient dqRedissonClient;
private RBlockingDeque<String> blockingDeque;
private RDelayedQueue<String> delayedQueue;
public void init() {
blockingDeque = dqRedissonClient.getBlockingDeque(BL_QUEUE_NAME);
delayedQueue = dqRedissonClient.getDelayedQueue(blockingDeque);
}
// ...
使用:
- 推消息:
delayedQueue.offer(msg, delay, timeUnit); - 获取消息:
blockingDeque.take();注意,该方法为阻塞方法,本质上为BLPOP操作
Redisson 延时队列图解
使用 Redisson 延迟队列导致内存泄漏
https://mori.plus/archives/redisson_oom_fix
Comments